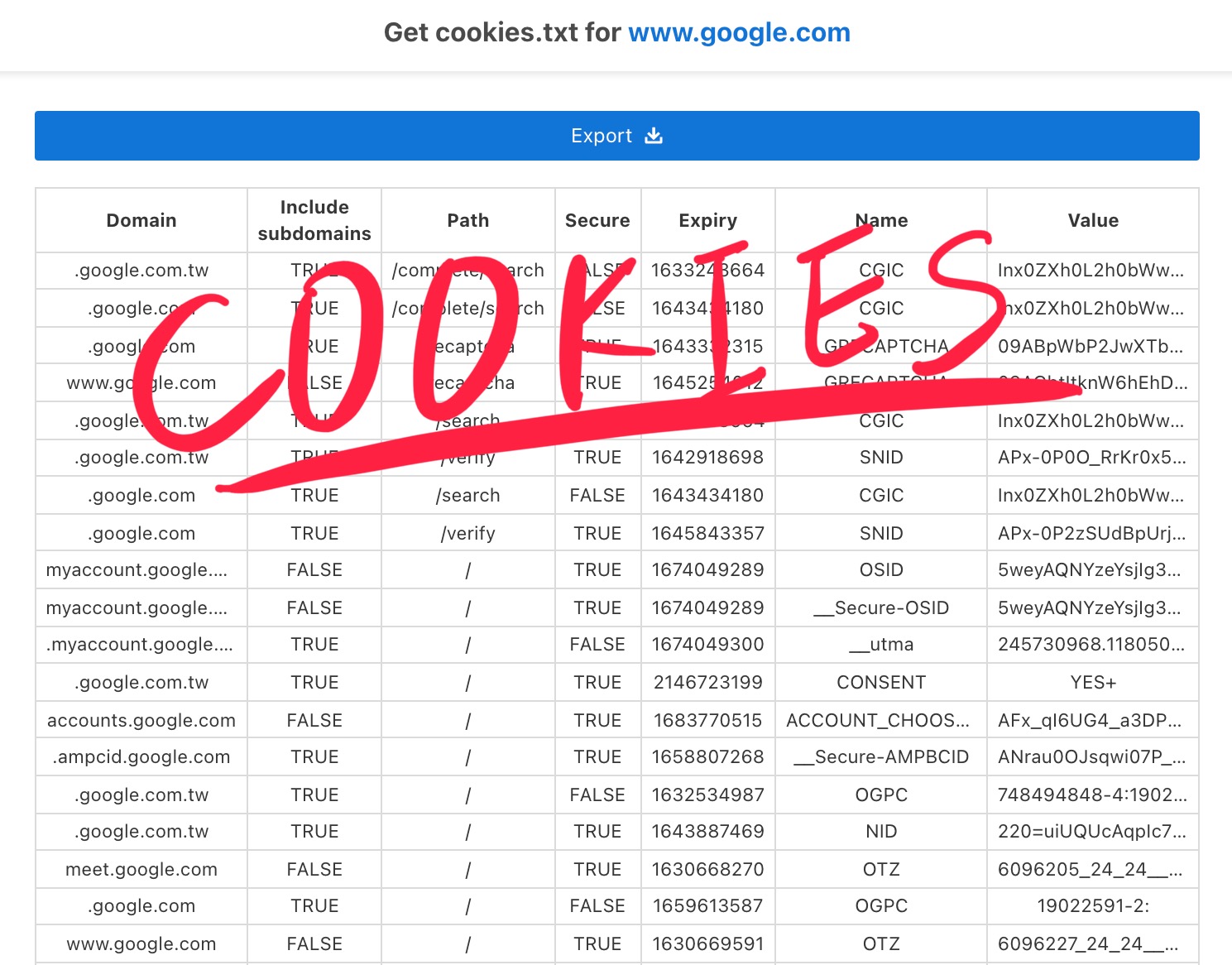
在做資料爬取的時候,某些頁面是要登入帳號後,才能做相關的取得。如果網站的要求沒有那麼多的話,在登入的頁面,可以簡單的利用帳號密碼完成登入,但有些網站為了防堵機器人,由其引進的 Google Captcha 的網頁,這時可以利用瀏覽器先手動登入,取得 cookies 後再另外儲存,方便之後使用。
解決問題
之前我都是使用 Edge 的開發人員工具,複製 cookies 進程式碼編寫,有些網站 cookies 數量很多的話,要一一篩選,然後進程碼式修改,但後來發現有 Get cookies.txt 可以使用,先登入好網頁後,會顯示該網頁正在使用的 cookies,可以直接下載存檔。

程式碼
指定好 cookiesname ,利用以下代碼就可以將檔案讀成 cookies:
def load_cookies():
cookiesname = 'google.com_cookies.txt'
my_cookie = ''
f = open(cookiesname, 'r')
lines = f.readlines()
for line in lines[4:]:
linesp = line.split()
my_cookie += (f'{linesp[-2]}={linesp[-1]};')
f.close()
return my_cookie之後要使用 GET 或是 POST 的時候,將自己的 cookies 代入即可。